
如果能搞清楚MySQL是如何优化和执行查询的,对优化查询一定会有帮助。很多查询优化实际上就是遵循一些原则让优化器能够按期望的合理的方式运行。
下图是MySQL执行一个查询的过程。实际上每一步都比想象中的复杂,尤其优化器,更复杂也更难理解。本文只给予简单的介绍。
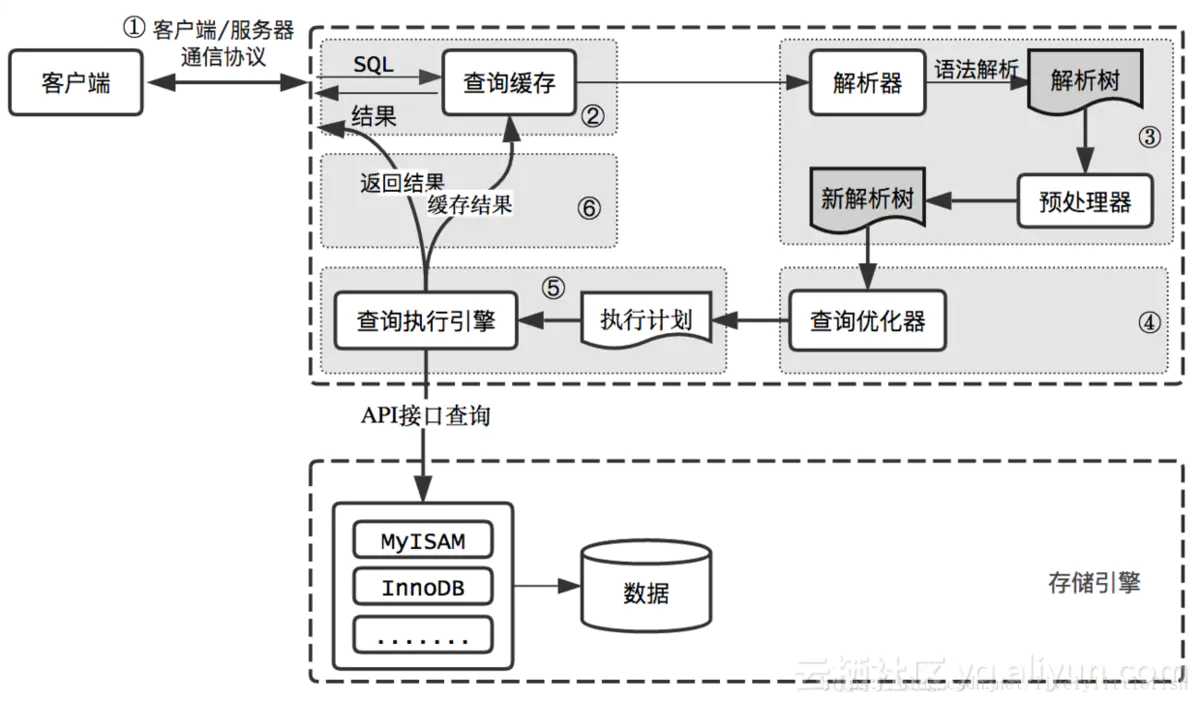
MySQL查询过程如下:
1.客户端将查询发送到MySQL服务器;
2.服务器先检查查询缓存,如果命中,立即返回缓存中的结果;否则进入下一阶段;
3.服务器对SQL进行解析、预处理,再由优化器生成对象的执行计划;
4.MySQL根据优化器生成的执行计划,调用存储引擎API来执行查询;
5.服务器将结果返回给客户端,同时缓存查询结果;

各属性含义:
id:
select查询序列号,id相同,执行顺序由上至下;id不同,id值越大优先级越高,越先被执行。
select_type:查询的类型,主要是区别普通查询和联合查询、子查询之类的复杂查询
- SIMPLE:查询中不包含子查询或者UNION
- 查询中若包含任何复杂的子部分,最外层查询则被标记为:PRIMARY
- 在SELECT或WHERE列表中包含了子查询,该子查询被标记为:SUBQUERY
- DERIVED:在from列表中包含的子查询被标记为derived(衍生),mysql或递归执行这些子查询,把结果放在零时表里。
- UNION:若第二个select出现在union之后,则被标记为union;若union包含在from子句的子查询中,外层select将被标记为derived。
- UNION RESULT:从union表获取结果的select。
table:输出的行所引用的表
type:访问类型

从左至右,性能由差到好
- ALL:扫描全表
- index:扫描全部索引树
- range:扫描部分索引,索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行,常见于between、<、>等的查询
- ref:使用非唯一索引或非唯一索引前缀进行的查找
- eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描
- const:单表中最多有一个匹配行,查询起来非常迅速,例如根据主键或唯一索引查询。
- system:system是const类型的特例,当查询的表只有一行的情况下, 使用system。
- NULL:不用访问表或者索引,直接就能得到结果,如select 1 from test where 1
possible_keys:表示查询时可能使用的索引。如果是空的,没有相关的索引。这时要提高性能,可通过检验WHERE子句,看是否引用某些字段,或者检查字段不是适合索引。(但不一定被查询实际使用)
key:显示MySQL实际决定使用的索引。如果没有索引被选择,是NULL
key_len:使用到索引字段的长度
注:key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。(表示索引中使用的字节数,通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好显示的是索引字段的最大长度,并非实际使用长度)
ref:显示哪个字段或常数与key一起被使用
rows:这个数表示mysql要遍历多少数据才能找到,表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数,在innodb上可能是不准确的。
filtered:
返回结果的行数占读取行数的百分比,值越大越好;
Extra:执行情况的说明和描述。包含不适合在其他列中显示但十分重要的额外信息。
- Distinct:一旦mysql找到了与行相联合匹配的行,就不再搜索了。
- Using filesort :mysql对数据使用一个外部的索引排序,而不是按照表内的索引进行排序读取。也就是说mysql无法利用索引完成的排序操作成为“文件排序” 。
- Using index :表示使用索引,如果只有 Using index,说明他没有查询到数据表,只用索引表就完成了这个查询,这个叫覆盖索引。即列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表的全部的请求列都是同一个索引的部分的时候。
- Using temporary :使用临时表保存中间结果,也就是说mysql在对查询结果排序时使用了临时表,常见于order by 和 group by。
- Using where :使用了where过滤。表示条件查询,如果不读取表的所有数据,或不是仅仅通过索引就可以获取所有需要的数据,则会出现 Using where。
- Using join buffer :使用了链接缓存。
- select tables optimized away: 在没有group by子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT操作,不必等到执行阶段在进行计算,查询执行计划生成的阶段即可完成优化。
参考:https://www.cnblogs.com/ggjucheng/archive/2012/11/11/2765237.html