
1. 查看备库(或者主库)的状态
SET feed off
SET lines 300
SET pages 999
COLUMN database_name heading "Database|Name" FORMAT a12
COLUMN database_role heading "Database|Role" FORMAT a30
COLUMN protection_mode heading "Protection|Mode" FORMAT a30
COLUMN force_logging heading "Force|Logging" FORMAT a7
COLUMN open_mode heading "Open|Mode" FORMAT a30
COLUMN switchover_status heading "Switchover|Status" FORMAT a30
SELECT name AS database_name,
protection_mode,
database_role,
force_logging,
open_mode,
switchover_status
FROM v$database;-
主库:

-
备库:

2. 查询主库日志传输序列号、备库日志应用序列号
SELECT AL.THRD "Thread",
ALMAX "Last Seq Received",
LHMAX "Last Seq Applied"
FROM (SELECT THREAD# THRD, MAX(SEQUENCE#) ALMAX
FROM V$ARCHIVED_LOG
WHERE RESETLOGS_CHANGE# =
(SELECT RESETLOGS_CHANGE# FROM V$DATABASE)
GROUP BY THREAD#) AL,
(SELECT THREAD# THRD, MAX(SEQUENCE#) LHMAX
FROM V$LOG_HISTORY
WHERE RESETLOGS_CHANGE# =
(SELECT RESETLOGS_CHANGE# FROM V$DATABASE)
GROUP BY THREAD#) LH
WHERE AL.THRD = LH.THRD;如果相等则表示主、备库数据一致。反之则主、备库数据不一致。

3. 检查备库是否有MRP0进程以及进程的活动状态
SELECT process,client_process,sequence#,status
FROM v$managed_standby;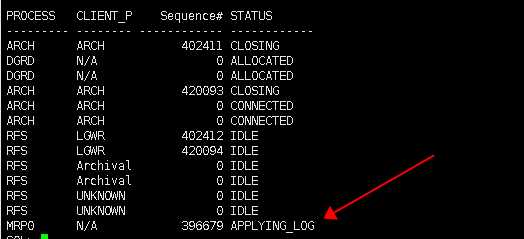
特别说明:
RFS(remote file server):运行在备库上的进程,用于在备库上进行主库的日志恢复。默认,这个进程用于接收从主库传送过来的归档日志。
MRP:当物理备库启用了实时应用的时候,会创建这个进程,用于日志的实时应用。
1)启用MRP 进程,后台恢复进程应用standby redo logfile进行恢复:
SQL> alter database recover managed standby database using current logfile disconnect from session;2)取消MRP进程应用:
SQL> alter database recover managed standby database cancel;2021-09-11T15:07:02.974994+08:00
rfs (PID:48850): Selected LNO:12 for T-1.S-420302 dbid 4207424032 branch 1007720356
2021-09-11T15:07:03.050442+08:00
ARC2 (PID:29688): Archived Log entry 533128 added for T-1.S-420301 ID 0xfae8807e LAD:1
2021-09-11T15:07:03.235054+08:00
PR00 (PID:30407): Media Recovery Waiting for T-1.S-420302 (in transit)
2021-09-11T15:07:03.235977+08:00
Recovery of Online Redo Log: Thread 1 Group 12 Seq 420302 Reading mem 0
Mem# 0: /dbData/OracleArch/LZUDG/onlinelog/group_12.890.1009669475
- CLIENT_PROCESS 对应 Primary 数据库中的进程如 ARCH\LGWR等
- SEQUENCE#:归档序号
- STATUS 当前进程状态:
| 进程状态名称 | 进程状态描述 |
|---|---|
| CONNECTED | 已连接至 PRIMARY 数据库 |
| ALLOCATED | 正在准备连接PRIMARY数据库 |
| ATTACHED | 正在连接PRIMARY数据库 |
| IDLE | 空闲中 |
| RECEIVING | 正在接收归档文件 |
| OPENNING | 正在处理归档文件 |
| CLOSING | 归档文件已处理完,收尾中 |
| WRITING | 正在向归档文件中写入redo数据 |
| WAIT_FOR_LOG | 正在等待新的REDO数据 |
| WAIT_FOR_GAP | 归档发生中断,正在等待新的REDO 数据 |
| APPLYING_LOG | 正在应用REDO数据 |
4. 检查备库日志应用的情况
SELECT registrar,
creator,
thread#,
applied,
sequence#,
first_change#,
next_change#,
completion_timE
FROM v$archived_log
WHERE completion_time > TRUNC(SYSDATE);日志应用的日期范围自己手动调整.

5. 检查real-time apply 应用日志的进度
SET feed off
SET lines 300
SET pages 999
SELECT to_char(sysdate, 'yyyymmdd hh24:mi:ss') ctime,
name,
value,
datum_time
FROM v$dataguard_stats
WHERE NAME LIKE '%lag';
其中如果apply lag对应的value大于0,那么就需要注意检查是否同步正常。如果相差时间非常多,value值等于几分钟,甚至达到1个小时,那可能实时同步有问题,需要检查 alert log 文件,其中会提示是否启动了real time apply。
如果已经启动了real time apply,apply lag 还是常常大于0,那么可能是DG上standby redo log 的问题,如果standby redo log增加不正确,那么可以在alert log中找到类似如下的语句:
RFS[1]: No Standby redo logfiles created for thread 1那么可能是standby redo log没有在DG上创建,也有可能创建了,但是thread错误导致。 可以通过查看
set lines 200 pages 9999 LONG 5000
col member for a80
SELECT a.thread#,a.group#,b.member,b.type,a.bytes/1024/1024 MB, a.sequence#, a.status
FROM v$log a,v$logfile b
WHERE a.group# = b.group#
UNION ALL
SELECT a.thread#,a.group#,b.member,b.type,a.bytes/1024/1024 MB, a.sequence#, a.status
FROM v$standby_log a,v$logfile b
WHERE a.group# = b.group#;
如果创建了standby redo log , 那么在应用redo时,一定有至少1个standby redo log的状态是 ACTIVE 的,其他大多数是 unassigned . 如果都是 UNASSIGNED ,那么就是standby redo log的问题。
6. 检查是否有GAP
SELECT *
FROM v$archive_gap;物理备库上的 V$ARCHIVE_GAP 固定视图只返回当前阻止重做应用继续的下一个间隙
上一刻备库是没有GAP的,但是下一秒中却出现了GAP:
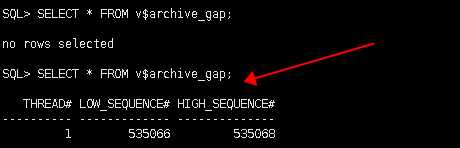
在解决标识的间隙(GAP)并启动redo apply之后,再次查询物理备用数据库上的 V$ARCHIVE_gap 视图,以确定下一个间隙序列(如果有)。重复此过程,直到没有更多间隙。
WITH prod AS
(SELECT dest_id, MAX(sequence#) AS seq
FROM v_$archived_log
WHERE resetlogs_time = (SELECT resetlogs_time FROM v_$database)
GROUP BY dest_id),
stby AS
(SELECT MAX(sequence#) AS seq, dest_id dest_id
FROM v_$archived_log
WHERE first_change# > (SELECT resetlogs_change# FROM v_$database)
AND applied = 'YES'
AND dest_id IN (1, 2)
GROUP BY dest_id)
SELECT prod.seq - stby.seq, stby.dest_id
FROM prod, stby
WHERE prod.dest_id = stby.dest_id;