
Oralce Database Reference:https://docs.oracle.com/en/database/oracle/oracle-database/19/refrn/index.html
1. 数据库总体运行情况
1.1. 数据库运行时间查询
- 单实例数据库
COL host_name FORMAT a10 HEADING "Host" NEWLINE
COL instance_name FORMAT a8 HEADING "Instance" NEWLINE
COL stime FORMAT a40 HEADING "Database Started At" NEWLINE
COL uptime FORMAT a80 HEADING "Uptime" NEWLINE
SET HEADING OFF
SELECT 'Hostname : ' || host_name
,'Instance Name : ' || instance_name
,'Started At : ' || to_char(startup_time,'DD-MON-YYYY HH24:MI:SS') stime
,'Uptime : ' || floor(sysdate - startup_time) || ' days(s) ' ||
trunc( 24*((sysdate-startup_time) -
trunc(sysdate-startup_time))) || ' hour(s) ' ||
mod(trunc(1440*((sysdate-startup_time) -
trunc(sysdate-startup_time))), 60) ||' minute(s) ' ||
mod(trunc(86400*((sysdate-startup_time) -
trunc(sysdate-startup_time))), 60) ||' seconds' uptime
FROM v$instance;- RAC数据库
COL host_name FORMAT a10 HEADING "Host" NEWLINE
COL instance_name FORMAT a8 HEADING "Instance" NEWLINE
COL stime FORMAT a40 HEADING "Database Started At" NEWLINE
COL uptime FORMAT a80 HEADING "Uptime" NEWLINE
SET heading off
SELECT 'Hostname : ' || host_name
,'Instance Name : ' || instance_name
,'Started At : ' || to_char(startup_time,'DD-MON-YYYY HH24:MI:SS') stime
,'Uptime : ' || floor(sysdate - startup_time) || ' days(s) ' ||
trunc( 24*((sysdate-startup_time) -
trunc(sysdate-startup_time))) || ' hour(s) ' ||
mod(trunc(1440*((sysdate-startup_time) -
trunc(sysdate-startup_time))), 60) ||' minute(s) ' ||
mod(trunc(86400*((sysdate-startup_time) -
trunc(sysdate-startup_time))), 60) ||' seconds' uptime
FROM gv$instance;数据库如果 HANG 住了,最优先排查的就是会话和等待事件!!!
1.2. 当前时刻活动的会话(按用户统计)
SET feed off
SET lines 300 pages 999
column username format a20
column machine format a40
SELECT a.username,a.machine,count(*)
FROM gv$session a
-- WHERE a.status = 'ACTIVE'
GROUP BY a.username,machine
ORDER BY 3 desc;- 或查询进程
SET feed off
SET lines 300 pages 999
column username format a20
column machine format a40
SELECT b.username,b.machine,b.program, COUNT(*)
FROM v$process a
LEFT JOIN v$session b ON a.addr = b.paddr
GROUP BY b.username,b.machine,b.program
ORDER BY 4 DESC;1.3. 查询会话的等待事件
SET LINES 300 PAGES 999
COLUMN inst_id HEADING "Inst_ID" FORMAT 999999
COLUMN sid HEADING "Session_ID" FORMAT 9999999999999
COLUMN serial# HEADING "Session_Serial#" FORMAT 9999999999
COLUMN sql_id HEADING "Sql_ID" FORMAT A16
COLUMN machine HEADING "machine" FORMAT A16
COLUMN username HEADING "User_Name" FORMAT A16
COLUMN event HEADING "event" FORMAT A30
COLUMN blocking_session HEADING "Blocking_Session" FORMAT 9999999999999
SELECT sid, serial#, inst_id, sql_id, event, p1,p2,p3, machine, username, blocking_session
FROM gv$session
WHERE wait_class# <> 6;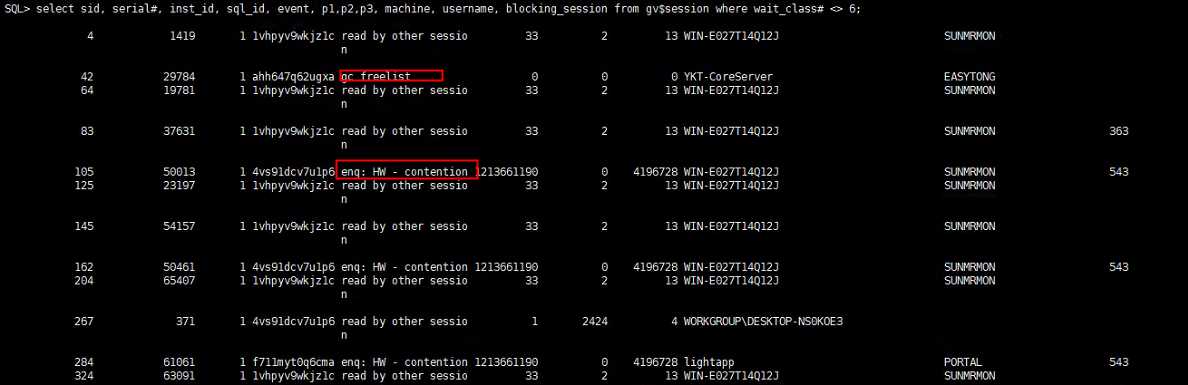
1.4. 当前时刻活动会话正在执行的SQL
SET LINES 300 PAGES 999
COL username FOR A12
COLUMN inst_id HEADING "Inst_ID" FORMAT 999999
COLUMN sid HEADING "Session_ID" FORMAT 9999999999999
COLUMN serial# HEADING "Session_Serial#" FORMAT 9999999999
COLUMN event HEADING "Event" FORMAT A20
COLUMN wait_class HEADING "wait_class" FORMAT A12
COLUMN action HEADING "action" FORMAT A12
COL sql_text FOR A50
SELECT s.username,
s.sid,
s.serial#,
s.inst_id,
s.event,
s.wait_class,
to_char(s.sql_exec_start,'yyyy-MM-dd hh24:mi:ss') AS sql_exec_start,
s.seconds_in_wait,
s.action,
sq.sql_text
FROM gv$session s, gv$sqlarea sq
WHERE s.status = 'ACTIVE'
AND s.username IS NOT NULL
AND s.inst_id = sq.inst_id
AND s.sql_id = sq.sql_id
AND s.sid <> USERENV('SID');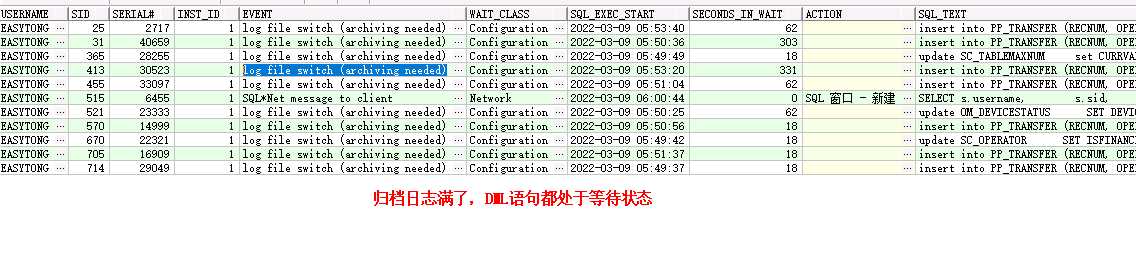
或 结合未提交的事务进行查询:
WITH transaction_details AS
(SELECT inst_id,
ses_addr,
SYSDATE - start_date AS diff
FROM gv$transaction)
SELECT s.username,
TO_CHAR(TRUNC(t.diff)) || ' days, ' ||
TO_CHAR(TRUNC(MOD(t.diff * 24,24))) || ' hours, ' ||
TO_CHAR(TRUNC(MOD(t.diff * 24 * 60,24))) || ' minutes, ' ||
TO_CHAR(TRUNC(MOD(t.diff * 24 * 60 * 60, 60))) || ' seconds' AS TRANSACTION_DURATION,
s.program,
s.terminal,
s.status,
s.sid,
s.serial#
FROM gv$session s, transaction_details t
WHERE s.inst_id = t.inst_id
AND s.saddr = t.ses_addr
ORDER BY t.diff DESC1.5. 数据库长时间执行的SQL
- NON RAC
SET LINES 300 PAGES 999
COL username FOR A12
COLUMN sid HEADING "Session_ID" FORMAT 9999999999999
COLUMN serial# HEADING "Session_Serial#" FORMAT 9999999999
COLUMN opname HEADING "op_name" FORMAT A20
COLUMN progress HEADING "progress" FORMAT A20
COLUMN sql_text HEADING "sql_text" FORMAT A120
SELECT sl.username,
sl.sid,
sl.serial#,
sl.opname,
ROUND(sl.sofar * 100 / sl.totalwork, 0) || '%' AS progress,
sl.time_remaining,
sq.sql_text
FROM v$session_longops sl, v$sql sq
WHERE sl.time_remaining <> 0
AND sl.sql_address = sq.address
AND sl.sql_hash_value = sq.hash_value;- RAC
SET LINES 300 PAGES 999
COL username FOR A12
COLUMN inst_id HEADING "Inst_ID" FORMAT 999999
COLUMN sid HEADING "Session_ID" FORMAT 9999999999999
COLUMN serial# HEADING "Session_Serial#" FORMAT 9999999999
COLUMN sql_text HEADING "sql_text" FORMAT A120
SELECT a.inst_id, a.sid, a.serial#, a.username, a.sql_id, c.sql_text -- , c.sql_fulltext, b.*
FROM gv$session a, gv$session_longops b, gv$sql c
WHERE a.sid = b.sid
AND a.serial# = b.serial#
AND a.inst_id = b.inst_id
AND a.inst_id = c.inst_id
AND a.sql_id = c.sql_id;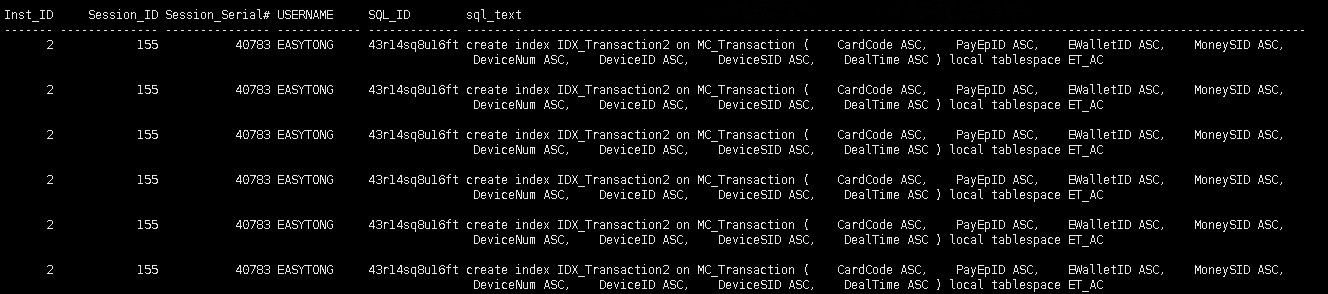
动态性能视图 v$session_longops、gv$session_longops
该视图记录了执行时间长于6秒的某个操作(这些操作可能是备份,恢复,收集统计信息,Hash Join,Sort ,Nested loop,Table Scan, Index Scan 等等),这个视图通常用来分析SQL运行缓慢的原因,配合 V$SESSION 视图。
1.必须将初始化参数 timed_statistics设置为true或者开启sql_trace
2.必须用ANALYZE或者DBMS_STATS对对象收集过统计信息
| 字段名 | 含义 | 字段名 | 含义 |
|---|---|---|---|
| SID | Session标识 | TIMESTAMP | 操作的时间戳 |
| SERIAL# | Session串号 | TIME_REMAINING | 预计完成操作的剩余时间(秒) |
| OPNAME | 操作简要说明 | ELAPSED_SECONDS | 从操作开始总花费时间(秒) |
| TARGET | 操作运行所在的对象 | CONTEXT | 前后关系 |
| TARGET_DESC | 目标对象说明 | MESSAGE | 统计项的完整描述 |
| SOFAR | 至今为止完成的工作量 | USERNAME | 执行操作的用户ID |
| TOTALWORK | 总工作量 | SQL_ADDRESS | 关联v$sql |
| UNITS | 工作量单位 | SQL_HASH_VALUE | 关联v$sql |
| START_TIME | 操作开始时间 | SQL_ID | 关联v$sql |
| LAST_UPDATE_TIME | 统计项最后更新时间 | QCSID | 主要是并行查询一起使用 |
- 查看执行的进度
SET LINE 300 PAGESIZE 9999
COL USERNAME FORMAT A10
COL SESSION_INFO FORMAT A30
COL TARGET FORMAT A20
COL OPNAME FORMAT A25
COL MESSAGE FORMAT A60
COL SOFAR_TOTALWORK FORMAT A20
COL PROGRESS FORMAT A8
SELECT a.username,
(SELECT nb.sid || ',' || nb.serial# || ',' || pr.spid || ',' ||nb.osuser|| ',' ||nb.status|| ',' ||nb.event
FROM gv$process pr, gv$session nb
WHERE nb.paddr = pr.addr
AND nb.sid = a.sid
AND nb.serial# = a.serial#
AND pr.inst_id = nb.inst_id
AND a.inst_id = nb.inst_id) session_info,
a.target,
a.opname,
TO_CHAR(a.start_time, 'yyyy-MM-dd hh24:mi:ss') AS start_time,
ROUND(a.sofar * 100 / a.totalwork, 2) || '%' AS progress,
(a.sofar || ':' || a.totalwork) AS sofar_totalwork,
a.time_remaining AS time_remaining,
a.elapsed_seconds AS elapsed_seconds,
message AS message
FROM gv$session_longops a
WHERE a.time_remaining <> 0
ORDER BY a.time_remaining desc, a.sql_id, a.sid;
1.6. 查看数据库历史的负载
SET LINES 300 PAGES 999
SELECT *
FROM (SELECT a.instance_number,
a.snap_id,
b.begin_interval_time + 0 AS begin_time,
b.end_interval_time + 0 AS end_time,
ROUND(VALUE - LAG(VALUE, 1 , '0') OVER(ORDER BY a.instance_number, a.snap_id)) AS "DB TIME"
FROM (SELECT b.snap_id,
instance_number,
SUM(VALUE) / 1000000 / 60 AS VALUE
FROM dba_hist_sys_time_model b
WHERE b.dbid = (SELECT dbid FROM v$database)
AND UPPER(b.stat_name) IN UPPER('DB TIME')
GROUP BY b.snap_id, instance_number) a, dba_hist_snapshot b
WHERE a.snap_id = b.snap_id
AND b.dbid = (SELECT dbid FROM v$database)
AND b.instance_number = a.instance_number)
WHERE TO_CHAR(begin_time, 'yyyy-MM-dd') = TO_CHAR(SYSDATE , 'yyyy-MM-dd')
ORDER BY begin_time;1.7. 查询执行慢的SQL
-- NON RAC,查询完整的SQL可以根据sql_id查询
SET LINES 300 PAGES 999
COL user_name FOR A12
COL sql_text FOR A100
SELECT *
FROM (SELECT sa.sql_id AS sql_id,
sa.executions AS executions,
round(sa.elapsed_time / 1000000, 2) AS sum_elapsed_time,
round(sa.elapsed_time / 1000000 / sa.executions, 2) AS avg_execute_time,
sa.command_type AS command_type,
sa.parsing_user_id AS user_id,
u.username AS user_name,
sa.hash_value AS hash_value,
sa.sql_text AS sql_text
-- sql_fulltext
FROM v$sqlarea sa
LEFT JOIN all_users u ON sa.parsing_user_id = u.user_id
WHERE sa.executions > 0
ORDER BY (sa.elapsed_time / sa.executions) desc)
WHERE rownum <= 50;1.8. 查询日志切换频率
包含RAC所有实例
SET LINES 300 PAGES 999
COL H00 FOR 9999
COL H01 FOR 9999
COL H02 FOR 9999
COL H03 FOR 9999
COL H04 FOR 9999
COL H05 FOR 9999
COL H06 FOR 9999
COL H07 FOR 9999
COL H08 FOR 9999
COL H09 FOR 9999
COL H10 FOR 9999
COL H11 FOR 9999
COL H12 FOR 9999
COL H13 FOR 9999
COL H14 FOR 9999
COL H15 FOR 9999
COL H16 FOR 9999
COL H17 FOR 9999
COL H18 FOR 9999
COL H19 FOR 9999
COL H20 FOR 9999
COL H21 FOR 9999
COL H22 FOR 9999
COL H23 FOR 9999
SELECT TO_CHAR(FIRST_TIME, 'MM/DD') DAY,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '00', 1, 0)) H00,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '01', 1, 0)) H01,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '02', 1, 0)) H02,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '03', 1, 0)) H03,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '04', 1, 0)) H04,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '05', 1, 0)) H05,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '06', 1, 0)) H06,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '07', 1, 0)) H07,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '08', 1, 0)) H08,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '09', 1, 0)) H09,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '10', 1, 0)) H10,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '11', 1, 0)) H11,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '12', 1, 0)) H12,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '13', 1, 0)) H13,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '14', 1, 0)) H14,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '15', 1, 0)) H15,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '16', 1, 0)) H16,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '17', 1, 0)) H17,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '18', 1, 0)) H18,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '19', 1, 0)) H19,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '20', 1, 0)) H20,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '21', 1, 0)) H21,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '22', 1, 0)) H22,
SUM(DECODE(TO_CHAR(FIRST_TIME, 'HH24'), '23', 1, 0)) H23,
COUNT(*) AS TOTAL
FROM (SELECT rownum rn, first_time
FROM gv$log_history
WHERE first_time > SYSDATE - 18
AND first_time > ADD_MONTHS(SYSDATE, -1)
ORDER BY first_time)
GROUP BY TO_CHAR(first_time, 'MM/DD')
ORDER BY MIN(RN);1.9. 查看闪回区的使用率
SET LINES 300 PAGES 999
COL name FOR A40
COL limit_gb FOR 99999999999999999
COL used_gb FOR 99999999999999999
COL space_reclaimable FOR 99999999999999999
SELECT name,
space_limit / 1024 / 1024 / 1024 AS limit_gb,
space_used / 1024 / 1024 / 1024 AS used_gb,
space_reclaimable / 1024 / 1024 / 1024 AS space_reclaimable,
number_of_files,
con_id
FROM v$recovery_file_dest;1.10. 容器数据库字符集
SET LINES 300 PAGES 999 FEED OFF
COLUMN value HEADING "Parameter|Value" FORMAT a30
SELECT value
FROM nls_database_parameters
WHERE parameter = 'NLS_CHARACTERSET';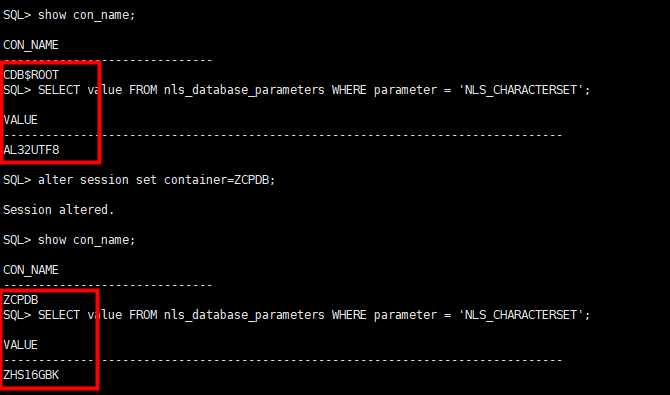
1.11. 查看数据库安装的组件
SET LINES 300 PAGES 999 FEED OFF
COL COMP_ID FOR A10
COL COMP_NAME FOR A60
COL VERSION FOR A20
COL STATUS FOR A20
SELECT comp_id, comp_name, version, status
FROM dba_registry
ORDER BY 1;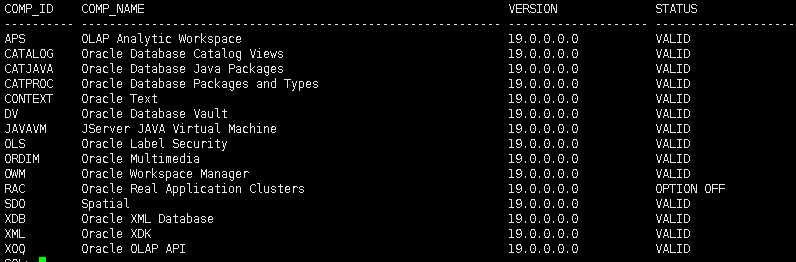
1.12. 查看数据库版本号
SET LINES 300 PAGES 999 FEED OFF
COL product FORMAT A42
COL version FORMAT A20
COL status FORMAT A30
SELECT product, version, status
FROM product_component_version;或:
SET LINES 120 PAGES 999 HEADING OFF
COL con_id FORMAT 999 HEADING "ContainerID" NEWLINE
COL banner FORMAT a120 HEADING "Banner" NEWLINE
COL banner_full FORMAT a120 HEADING "Banner Full" NEWLINE
COL banner_legacy FORMAT a20 HEADING "Banner Legacy" NEWLINE
SELECT 'ContainerID : ' || con_id,
'Banner : ' || banner,
'Banner Full : ' || banner_full,
'Banner Legacy: ' || banner_legacy
FROM v$version;
字段 banner 的含义:组件名称和版本号
字段 banner_full 的含义: Oracle Database 18c 中引入的新的 2 行横幅格式。 横幅显示数据库版本和版本号。
字段 banner_legacy 的含义: Oracle Database 18c 之前使用的旧版 1 行横幅。 此列显示与 BANNER 列相同的值。
字段 con_id 的含义: 数据所属容器的 ID。 可能的值包括:0:此值用于包含与整个 CDB 相关的数据的行。 此值也用于非 CDB 中的行。1:此值用于包含仅与根相关的数据的行,n:其中 n 是包含数据的行的适用容器 ID。
Oracle版本号含义说明:
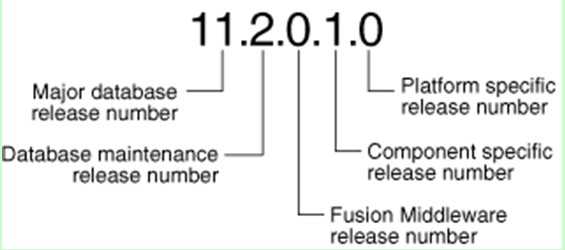
-
Major Database Release Number
第一个数字位,它代表的是一个新版本软件,也标志着一些新的功能。如11g,10g。 -
Database Maintenance Release Number
第二个数字位,代表一个maintenance release 级别,也可能包含一些新的特性。 -
Fusion Middleware Release Number
第三个数字位,反应Oracle 中间件(Oracle Fusion Middleware)的版本号。 -
Component-Specific Release Number
第四个数字位,主要是针对组件的发布级别。不同的组件具有不同的号码。 比如Oracle 的patch包。 -
Platform-Specific Release Number
第五个数字位,这个数字位标识一个平台的版本。 通常表示patch 号。
1.13. 查看数据库补丁
2. 当前会话
2.1. 查看当前用户的sid和serial
SET LINES 300 PAGES 999
COLUMN inst_id HEADING "Inst_ID" FORMAT 999999
COLUMN sid HEADING "Session_ID" FORMAT 9999999999999
COLUMN serial# HEADING "Session_Serial#" FORMAT 9999999999
COLUMN status HEADING "Status" FORMAT A20
SELECT inst_id,
sid,
serial#,
status
FROM gv$session
WHERE audsid = sys_context('USERENV', 'SESSIONID')
AND inst_id = sys_context('USERENV', 'INSTANCE');2.2. 查看当前会话的spid 与 trace file路径
SET LINES 300 PAGES 999
COLUMN inst_id HEADING "Inst_ID" FORMAT 999999
COLUMN sid HEADING "Session_ID" FORMAT 9999999999999
COLUMN serial# HEADING "Session_Serial#" FORMAT 9999999999
COLUMN spid HEADING "Process_ID" FORMAT A10
COLUMN status HEADING "Status" FORMAT A20
COLUMN tracefile HEADING "Trace_Fie" FORMAT A120
SELECT p.inst_id,
s.sid,
s.serial#,
p.spid,
s.status,
p.tracefile
FROM gv$process p, gv$session s
WHERE p.addr = s.paddr
AND s.audsid = userenv('sessionid')
AND s.inst_id = userenv('instance');2.3. 根据session相关信息查询操作系统进程号
SET LINES 300 PAGES 999
COL username FORMAT A12
COL machine FORMAT A30
COL program FORMAT A30
SELECT a.inst_id,
a.sid,
a.username,
a.status,
a.process,
a.machine,
a.program,
b.spid
FROM gv$session a, gv$process b
WHERE a.inst_id = b.inst_id
AND a.paddr = b.addr
AND a.osuser = '&osuser';根据 inst_id 与 spid,在操作系统层面使用 netstat 命令查询到与数据库连接的对端IP地址!
2.4. 已知spid,查看当前正在执行或最近一次执行的语句
-- NON RAC
SET LINES 300 PAGES 999
COLUMN sql_id FORMAT A20
COLUMN sql_text FORMAT A120
SELECT /*+ ordered */ sql_text, sql_id
FROM v$sqltext sql
WHERE (sql.hash_value, sql.address) IN (SELECT decode(sql_hash_value, 0, prev_hash_value, sql_hash_value),
decode(sql_hash_value, 0, prev_sql_addr, sql_address)
FROM v$session s
WHERE s.paddr = (SELECT addr
FROM v$process p
WHERE p.spid = to_number('&spid')))
ORDER BY piece ASC;2.5. 查询会话打开的游标数
SET LINES 300 PAGES 999
col MACHINE format a50
col OSUSER format a50
SELECT s.username,
o.sid,
osuser,
machine,
count(*) AS num_curs
FROM v$open_cursor o, v$session s
WHERE o.sid = s.sid
AND s.sid = '&sid'
AND s.serial# = '&serial'
GROUP BY s.username, o.sid, osuser, machine
ORDER BY num_curs desc;3. 阻塞与锁
3.1. 查看当前阻塞与被阻塞的会话
SET LINES 300 PAGES 999
COLUMN blocking_session HEADING "Blocking_Session" FORMAT A60
COLUMN blocked_session HEADING "Blocked_Session" FORMAT A60
COLUMN script HEADING "Kill_Session_SQL" FORMAT 40
COLUMN blocked_cnt HEADING 'Blocked_cnt' FORMAT 9999
SELECT blocking_session,blocked_session,script,blocked_cnt
FROM (SELECT DISTINCT
s1.username || '@' || s1.machine || ' ( INST=' || s1.inst_id || ' SID=' || s1.sid || ' ET=' || s1.last_call_et || 'sn. STATUS=' || s1.status || ' EVENT=' || s1.event || ' ACTION= ' || s1.action || ' PROGRAM=' || s1.program || ' MODULE=' || s1.module || ')' blocking_session,
s2.username || '@' || s2.machine || ' ( INST=' || s2.inst_id || ' SID=' || s2.sid || ' ET=' || s2.last_call_et || 'sn. STATUS=' || s2.status || ' EVENT=' || s2.event || ' ACTION= ' || s2.action || ' PROGRAM=' || s2.program || ' MODULE=' || s2.module || ')' blocked_session,
decode(s1.type,'USER','alter system kill session ''' || s1.sid || ',' || s1.serial# || ',@' || s1.inst_id || ''' immediate;' ,null)
script ,
COUNT(*) OVER(PARTITION BY s1.inst_id,s1.sid) blocked_cnt
FROM gv$lock l1, gv$session s1, gv$lock l2, gv$session s2
WHERE s1.sid=l1.sid
AND s2.sid=l2.sid
AND s1.inst_id=l1.inst_id
AND s2.inst_id=l2.inst_id
AND l1.block > 0
AND l2.request > 0
AND l1.id1 = l2.id1 and l1.id2 = l2.id2)
ORDER BY blocked_cnt DESC;3.2. 查询锁的源头SID
SELECT a.*,
row_number() over(partition by blocking_source order by "LEVEL" asc) as rn
FROM (SELECT *
FROM (SELECT inst_id,
lpad(' ', (level - 1) * 2, ' ') || sid AS sid,
serial#,
sql_id,
paddr,
username,
event,
machine,
program,
SUBSTR(numtodsinterval(seconds_in_wait, 'second'),
12,
8) as wait_time,
wait_class,
state,
level,
blocking_session,
(PRIOR sid) AS blocking_sid,
(PRIOR serial#) AS blocking_serial#,
(PRIOR sql_id) AS blocking_sql_id,
sys_connect_by_path(sid, '->') as blocking_path,
connect_by_root(sid) AS blocking_source
FROM gv$session
start with blocking_session is NULL
connect by (prior sid) = blocking_session)
WHERE "LEVEL" > 1
UNION
SELECT inst_id,
to_char(sid) as sid,
serial#,
sql_id,
paddr,
username,
event,
machine,
program,
SUBSTR(NUMTODSINTERVAL(seconds_in_wait, 'second'), 12, 8) as wait_time,
wait_class,
state,
1,
null,
null,
null,
null,
null,
sid
FROM gv$session
WHERE sid IN (SELECT blocking_source
FROM (SELECT wait_class#,
username,
level,
connect_by_root(sid) as blocking_source
FROM gv$session
START WITH blocking_session IS NULL
CONNECT BY (PRIOR sid) = blocking_session)
WHERE "LEVEL" > 1)) a;或
--使用v$session来查看RAC数据库和单实例阻塞session信息
SELECT
LPAD(' ',5*(LEVEL-1))||S."USERNAME" ,
LPAD(' ',5*(LEVEL-1))||S."INST_ID"||','||S."SID" ,
S."SERIAL#" ,
S."SQL_ID",
S."ROW_WAIT_OBJ#",
S."WAIT_CLASS",
S."EVENT",
S."P1",
S."P2",
S."P3",
S."SECONDS_IN_WAIT",
s."BLOCKING_INSTANCE"||','||s."BLOCKING_SESSION"
FROM GV$SESSION S
WHERE S."BLOCKING_SESSION" IS NOT NULL
OR (S."INST_ID"||','||S."SID") IN(SELECT DISTINCT BLOCKING_INSTANCE||','||BLOCKING_SESSION FROM GV$SESSION)
START WITH (s."BLOCKING_INSTANCE"||','||s."BLOCKING_SESSION") = ','
CONNECT BY PRIOR (S."INST_ID"||','||S."SID") = (s."BLOCKING_INSTANCE"||','||s."BLOCKING_SESSION");或:
SELECT r.root_sid,
s.serial#,
r.blocked_num,
TRUNC( r.avg_wait_seconds) AS avg_wait_seconds,
s.username,s.status,
s.event,s.MACHINE,
s.PROGRAM,
s.sql_id,
s.prev_sql_id
FROM (SELECT root_sid,
AVG(seconds_in_wait) AS avg_wait_seconds,
COUNT(*) - 1 AS blocked_num
FROM (SELECT CONNECT_BY_ROOT sid AS root_sid,
seconds_in_wait
FROM v$session
START WITH blocking_session IS NULL
CONNECT BY PRIOR SID = blocking_session)
GROUP BY root_sid HAVING COUNT(*) > 1
) r, v$session s
WHERE r.root_sid = s.sid;3.3. 查询数据库中被锁的对象
- 容器数据库
SET LINES 300 PAGES 999
COL pdb_name FORMAT A20
COL oracle_username FORMAT A15
COL os_user_name FORMAT A20
COL object_name FORMAT A30
COL machine FORMAT A20
COL terminal FORMAT A20
COL program FORMAT A15
SELECT lo.inst_id,
cp.pdb_name,
s.sid,
s.serial#,
lo.oracle_username,
lo.os_user_name,
ao.object_name,
lo.locked_mode,
s.machine,
s.terminal,
s.program
FROM gv$locked_object lo, cdb_objects ao, gv$session s, cdb_pdbs cp
WHERE ao.object_id = lo.object_id
AND lo.session_id = s.sid
AND lo.inst_id = s.inst_id
AND lo.con_id = cp.pdb_id;- 非容器数据库
SET LINES 300 PAGES 999
COL oracle_username FORMAT A15
COL os_user_name FORMAT A20
COL object_name FORMAT A30
COL machine FORMAT A20
COL terminal FORMAT A20
COL program FORMAT A15
SELECT lo.inst_id,
s.sid,
s.serial#,
lo.oracle_username,
lo.os_user_name,
ao.object_name,
lo.locked_mode,
s.machine,
s.terminal,
s.program
FROM gv$locked_object lo, dba_objects ao, gv$session s
WHERE ao.object_id = lo.object_id
AND lo.session_id = s.sid
AND lo.inst_id = s.inst_id;4. 表空间与数据库文件
4.1. 查看数据库表空间
- 容器数据库
SET LINES 300 PAGES 999
COL pdb_name FORMAT A30
COL tablespace_name FORMAT A20
SELECT b.con_id,
a.pdb_id,
a.pdb_name,
b.tablespace_name,
b.contents,
b.status,
b.bigfile
FROM dba_pdbs a
FULL OUTER JOIN cdb_tablespaces b ON a.pdb_id = b.con_id
ORDER BY b.con_id, b.tablespace_name;- 非容器数据库
SET LINES 300 PAGES 999
COL tablespace_name FORMAT A20
SELECT b.tablespace_name,
b.contents,
b.status,
b.bigfile
FROM dba_tablespaces b
ORDER BY b.tablespace_name;4.2. 查看数据库undo表空间所对应的数据文件
- 容器数据库
SET LINES 300 PAGES 999
COL pdb_name FORMAT A20
COL file_name FORMAT A90
COL tablespace_name FORMAT A20
SELECT a.con_id,
c.pdb_name,
b.tablespace_name,
a.retention,
b.file_id,
b.file_name,
b.autoextensible,
a.bigfile,
round(b.bytes / 1024 / 1024,2) AS undo_size_mb
FROM cdb_tablespaces a, cdb_data_files b, cdb_pdbs c
WHERE a.con_id = b.con_id
AND a.con_id = c.pdb_id
AND a.tablespace_name = b.tablespace_name
AND a.contents = 'UNDO'
ORDER BY a.con_id, b.tablespace_name, b.file_id;- 非容器数据库
SET LINES 300 PAGES 999
COL file_name FORMAT A90
COL tablespace_name FORMAT A20
SELECT b.tablespace_name,
a.retention,
b.file_id,
b.file_name,
b.autoextensible,
a.bigfile,
round(b.bytes / 1024 / 1024,2) AS undo_size_mb
FROM dba_tablespaces a, dba_data_files b
WHERE a.tablespace_name = b.tablespace_name
AND a.contents = 'UNDO'
ORDER BY b.tablespace_name, b.file_id;4.3. 查看数据库永久表空间所对应的数据文件
- 容器数据库
注意:容器数据库(即PDB)应处于READ WRITE状态,同时查询结果并不包含PDB$SEED以及cdb$root所创建的数据文件。
SET LINES 300 PAGES 999
COL pdb_name FORMAT A20
COL file_name FORMAT A90
COL tablespace_name FORMAT A20
SELECT a.con_id,
c.pdb_name,
b.tablespace_name,
a.retention,
b.file_id,
b.file_name,
b.autoextensible,
a.bigfile,
round(b.bytes / 1024 / 1024,2) AS permanent_size_mb
FROM cdb_tablespaces a, cdb_data_files b, cdb_pdbs c
WHERE a.con_id = b.con_id
AND a.con_id = c.pdb_id
AND a.tablespace_name = b.tablespace_name
AND a.contents = 'PERMANENT'
ORDER BY a.con_id, b.tablespace_name, b.file_id;- 非容器数据库
SET LINES 300 PAGES 999
COL file_name FORMAT A90
COL tablespace_name FORMAT A20
SELECT b.tablespace_name,
a.retention,
b.file_id,
b.file_name,
b.autoextensible,
a.bigfile,
round(b.bytes / 1024 / 1024,2) AS permanent_size_mb
FROM dba_tablespaces a, dba_data_files b
WHERE a.tablespace_name = b.tablespace_name
AND a.contents = 'PERMANENT'
ORDER BY b.tablespace_name, b.file_id;4.4. 查看数据库临时表空间所对应的数据文件
- 容器数据库
SET LINES 300 PAGES 999
COL pdb_name FORMAT A20
COL file_name FORMAT A90
COL tablespace_name FORMAT A20
SELECT a.con_id,
c.pdb_name,
b.tablespace_name,
a.retention,
b.file_id,
b.file_name,
b.autoextensible,
a.bigfile,
round(b.bytes / 1024 / 1024,2) AS temp_size_mb
FROM cdb_tablespaces a, cdb_temp_files b, cdb_pdbs c
WHERE a.con_id = b.con_id
AND a.con_id = c.pdb_id
AND a.tablespace_name = b.tablespace_name
AND a.contents = 'TEMPORARY'
ORDER BY a.con_id, b.tablespace_name, b.file_id;- 非容器数据库
SET LINES 300 PAGES 999
COL file_name FORMAT A90
COL tablespace_name FORMAT A20
SELECT b.tablespace_name,
a.retention,
b.file_id,
b.file_name,
b.autoextensible,
a.bigfile,
round(b.bytes / 1024 / 1024,2) AS temp_size_mb
FROM dba_tablespaces a, dba_temp_files b
WHERE a.tablespace_name = b.tablespace_name
AND a.contents = 'TEMPORARY'
ORDER BY b.tablespace_name, b.file_id;4.5. 查看数据库联机重做日志文件所对应的数据文件
SET LINES 300 PAGES 999
COLUMN member FORMAT A50
COLUMN first_change# FORMAT 99999999999999999999
COLUMN next_change# FORMAT 99999999999999999999
SELECT l.thread#,
lf.group#,
lf.member,
TRUNC(l.bytes/1024/1024) AS size_mb,
l.status,
l.archived,
lf.type,
lf.is_recovery_dest_file AS rdf,
l.sequence#,
l.first_change#,
l.next_change#
FROM v$logfile lf
JOIN v$log l ON l.group# = lf.group#
ORDER BY l.thread#,lf.group#, lf.member;4.6. 查看数据库归档日志文件所对应的数据文件
SET LINES 300 PAGES 999
COL NAME FORMAT A80
SELECT con_id,
inst_id,
name,
dest_id,
thread#,
sequence#,
standby_dest,
applied,
deleted,
status,
registrar,
completion_time,
block_size
FROM gv$archived_log
WHERE completion_time >= SYSDATE - 7;4.7. 查询表空间使用大小与剩余容量
- 容器数据库
set feed off lines 300 pages 999
column "TablespaceName" heading "表空间名称" format a20
column "FileCount" heading "文件个数" format 999999
column "UsedFileSize" heading "已使用的|文件大小(MB)" format 999,999,999.99
column "MaxFileSize" heading "最大|文件大小(MB)" format 999,999,999
column "UsedDiskSize" heading "已使用的|磁盘空间大小(MB)" format 999,999,999.99
column "UnusedDiskSize" heading "未使用的|磁盘空间大小(MB)" format 999,999,999.99
column "TotalAvailableDiskSize" heading "可使用的|全部磁盘空间大小(MB)" format 999,999,999.99
SELECT ts.tablespace_name AS TablespaceName,
df.FileCount AS FileCount,
TRUNC(df.UsedFileSize, 2) AS UsedFileSize,
df.MaxFileSize AS MaxFileSize,
TRUNC(df.UsedFileSize - fr.FreeDiskSize, 2) AS UsedDiskSize,
TRUNC(fr.FreeDiskSize, 2) AS UnusedDiskSize,
df.MaxFileSize - TRUNC(df.UsedFileSize - fr.FreeDiskSize, 2) AS TotalAvailableDiskSize
FROM (SELECT tablespace_name, SUM(bytes) / (1024 * 1024) AS FreeDiskSize
FROM cdb_free_space
GROUP BY tablespace_name) fr,
(SELECT tablespace_name,
TRUNC(SUM(bytes) / (1024 * 1024),2) AS UsedFileSize,
COUNT(*) AS FileCount,
TRUNC(SUM(maxbytes) / (1024 * 1024),2) AS MaxFileSize
FROM cdb_data_files
GROUP BY tablespace_name) df,
(SELECT tablespace_name FROM cdb_tablespaces) ts
WHERE fr.tablespace_name = df.tablespace_name(+)
AND fr.tablespace_name = ts.tablespace_name(+)
ORDER BY 7;- 非容器数据库
set feed off lines 300 pages 999
column "TablespaceName" heading "表空间名称" format a20
column "FileCount" heading "文件个数" format 999999
column "UsedFileSize" heading "已使用的|文件大小(MB)" format 999,999,999.99
column "MaxFileSize" heading "最大|文件大小(MB)" format 999,999,999
column "UsedDiskSize" heading "已使用的|磁盘空间大小(MB)" format 999,999,999.99
column "UnusedDiskSize" heading "未使用的|磁盘空间大小(MB)" format 999,999,999.99
column "TotalAvailableDiskSize" heading "可使用的|全部磁盘空间大小(MB)" format 999,999,999.99
SELECT ts.tablespace_name AS TablespaceName,
df.FileCount AS FileCount,
TRUNC(df.UsedFileSize, 2) AS UsedFileSize,
df.MaxFileSize AS MaxFileSize,
TRUNC(df.UsedFileSize - fr.FreeDiskSize, 2) AS UsedDiskSize,
TRUNC(fr.FreeDiskSize, 2) AS UnusedDiskSize,
df.MaxFileSize - TRUNC(df.UsedFileSize - fr.FreeDiskSize, 2) AS TotalAvailableDiskSize
FROM (SELECT tablespace_name, SUM(bytes) / (1024 * 1024) AS FreeDiskSize
FROM dba_free_space
GROUP BY tablespace_name) fr,
(SELECT tablespace_name,
TRUNC(SUM(bytes) / (1024 * 1024),2) AS UsedFileSize,
COUNT(*) AS FileCount,
TRUNC(SUM(maxbytes) / (1024 * 1024),2) AS MaxFileSize
FROM dba_data_files
GROUP BY tablespace_name) df,
(SELECT tablespace_name FROM dba_tablespaces) ts
WHERE fr.tablespace_name = df.tablespace_name(+)
AND fr.tablespace_name = ts.tablespace_name(+)
ORDER BY 7;以下更准确:
SELECT d.tablespace_name AS TablespaceName,
a.FileCount AS FileCount,
d.status AS TablespaceStatus,
to_char(NVL(a.bytes / 1024 / 1024, 0),'99G999G990D900') AS UsedFileSize,
to_char(NVL(a.max_bytes / 1024 / 1024, 0),'99G999G990D900') AS MaxFileSize,
to_char(NVL(a.bytes - NVL(f.bytes,0), 0) / 1024 / 1024, '99G999G990D900') AS UsedDiskSizeMb,
to_char(NVL(a.max_bytes - NVL(a.bytes - NVL(f.bytes,0), 0), 0) / 1024 / 1024, '99G999G990D900') AS TotalAvailableDiskSizeMb,
to_char(NVL((a.bytes - NVL(f.bytes,0)) / a.max_bytes * 100, 0), '990D00') AS UsedDiskPercent
FROM sys.dba_tablespaces d,
(SELECT tablespace_name,
COUNT(file_id) AS filecount,
SUM(bytes) bytes,
SUM(CASE WHEN autoextensible = 'NO' THEN bytes
WHEN autoextensible = 'YES' THEN maxbytes END) AS max_bytes
FROM dba_data_files
GROUP BY tablespace_name
UNION ALL
SELECT tablespace_name,
COUNT(file_id) AS filecount,
SUM(bytes) bytes,
SUM(CASE WHEN autoextensible = 'NO' THEN bytes
WHEN autoextensible = 'YES' THEN maxbytes END) AS max_bytes
FROM dba_temp_files
GROUP BY tablespace_name ) a,
(SELECT tablespace_name, SUM(bytes) bytes
FROM dba_free_space
GROUP BY tablespace_name) f
WHERE d.tablespace_name = f.tablespace_name(+)
AND d.tablespace_name = a.tablespace_name(+)
ORDER BY 7;4.8. 查询正在使用回滚段(UNDO)的会话(单实例)
SELECT s.sid,
s.serial#,
s.sql_id,
v.usn,
r.segment_name,
r.status,
v.rssize/1024/1024 mb
FROM dba_rollback_segs r, v$rollstat v, v$transaction t, v$session s
WHERE r.segment_id = v.usn
AND v.usn = t.xidusn
AND t.addr = s.taddr
ORDER BY r.segment_name;
5. 数据库CPU与内存
5.1. 查看数据库内存分配模式
ASMM(Automatic Shared Memory Management,自动共享内存管理 )是Oracle 10g引入的概念。即让设置一个SGA的目标值以及SGA的最大值,数据库来动态调整其中的各个组件,如Database buffer cache、Shared pool等等。
AMM:automatic memory management 自动内存管理 (11.1才有的特性) 即让数据库完全管理SGA、PGA的大小,而对于管理员只需要设置一个总的大小(memory_target),数据库会动态的调整SGA、PGA的大小以及其中包含的各个组件大小,如Database buffer cache、Shared pool等等。
ORACLE 11g AMM 的引入,组合出来有 5 种内存管理形式.
| 内存管理模式 | 设置规则 |
|---|---|
| 自动内存管理(AMM) | memory_target = 非0,是自动内存管理,如果初始化参数 LOCK_SGA=TRUE,则 AMM 是不可用的. |
| 自动共享内存管理(ASMM) | memory_target = 0 and sga_target为非0的情形下是自动内存管理. |
| 手工共享内存管理 | memory_target = 0 and sga_target = 0 指定 share_pool_size 、db_cache_size 等 sga 参数. |
| 自动 PGA 管理 | memory_target = 0 and workarea_size_policy=auto and PGA_AGGREGATE_TARGET=值. |
| 手动 PGA 管理 | memory_target = 0 and workarea_size_policy=manal 然后指定 SORT_AREA_SIZE 等 PGA 参数,一般不使用手动管理PGA. |
show parameter target;
show parameter memory_target;
show parameter sga_target;
show parameter pga_aggregate_target;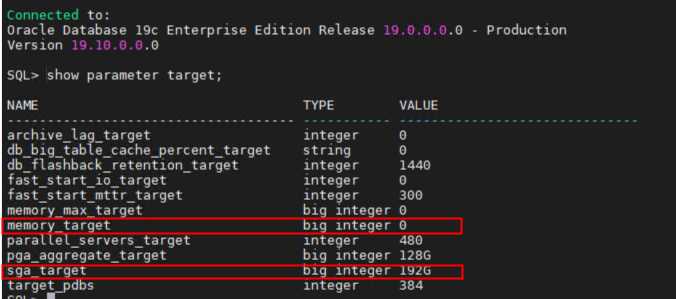
- 如果Memory_target 设置为非0 值
1、sga_target 和 pga_aggregate_target 已经设置大小
Memory_Target = SGA_TARGET + PGA_AGGREGATE_TARGET,其大小不能超过memory_max_size。
2、sga_target 设置大小, pga_aggregate_target 没有设置大小
pga_aggregate_target的初始化值 = memory_target - sga_target
3、sga_target 没有设置大小, pga_aggregate_target 设置大小
sga_target的初始化值 = memory_target - pga_aggregate_target
4、sga_target 和 pga_aggregate_target 都没有设置大小
两个值没有最小值和默认值,Oracle 将根据数据库运行状况进行分配大小,但在数据库启动是会有一个固定比例来分配:
sga_target = memory_target * 60%
pga_aggregate_target = memory_target * 40%- 如果Memory_target 设置为0
11g 中默认为0 则初始状态下取消了 Memory_target 的作用,完全和10g 在内存管理上一致,完全向下兼容。
1、SGA_TARGET设置值
自动调节SGA 中的shared pool,buffer cache,redo log buffer,java pool,larger pool等内存空间的大小。PGA 则依赖pga_aggregate_target 的大小。
2、SGA_target 和PGA_AGGREGATE_TARGET 都没有设置
SGA 中的各组件大小都要明确设定,不能自动调整各组件大小。PGA不能自动增长和收缩
3、MEMORY_MAX_TARGET 设置而 MEMORY_TARGET = 0 这种情况先和10g 一样。5.2. 查看数据库内存使用率
SET LINES 300 PAGES 999
COL NAME FORMAT A10
SELECT name,
ROUND(total,2) AS total_size_mb,
ROUND(total-free,2) AS used_size_mb,
ROUND(free,2) AS free_size_mb,
ROUND((total-free)/total*100,2) AS pctused
FROM (SELECT 'SGA' AS name,
(SELECT sum(value/1024/1024) FROM v$sga) AS total,
(SELECT sum(bytes/1024/1024) FROM v$sgastat WHERE name = 'free memory') AS free
FROM dual)
UNION
SELECT name,
ROUND(total,2) AS total_size_mb,
ROUND(used,2) AS used_size_mb,
ROUND(total-used,2) AS free_size_mb,
ROUND(used/total*100,2) AS pctused
FROM (SELECT 'PGA' name,
(SELECT value/1024/1024 total FROM v$pgastat WHERE name = 'aggregate PGA target parameter') AS total,
(SELECT value/1024/1024 used FROM v$pgastat WHERE name = 'total PGA allocated') AS used
FROM dual);
5.3. 19c 数据库启用 IN-Memory特性
启用IMO非常简单,12.1.0.2及之后版本下,设置INMEMORY_SIZE 为非0值便可启用IM column store特性。
INMEMORY_SIZE 是个实例级参数,默认为0,设置一个非0值时,最小值为100M。从 12.2 开始,可以动态增加 In-Memory 区域的大小,为此,只需 通过 ALTER SYSTEM 命令增加 INMEMORY_SIZE 参数值即可。它也不会受到自动内存管理 (AMM) 的影响或控制。
我们还可以在 CDB 和 PDB 级别设置 inmemory_size 参数。如果您在 PDB 级别设置此参数,则无需重新启动实例或 PDB。所有 PDB 值的总和小于或等于 CDB 值。
- 查询是否开启了inmemory
show parameter inmemory;
alter system set inmemory_size=10g scope=spfile sid='*';- 在grid用户下重启所有数据库实例
su - grid
srvctl status database -d racdb
srvctl stop database -d racdb
srvctl start database -d racdb-
表空间、表、(子)分区和实例化视图中启用 INMEMORY 属性。
如果在表空间级别启用此属性,则默认情况下将为 IMCOLUMN 存储启用表空间中的所有表和实例化视图。alter table test inmemory; -
监控 inmemory 中的对象
SET LINES 300 PAGES 999
COL pdb_name FORMAT A10
COL owner FORMAT A12
COL segment_name FORMAT A60
SELECT a.con_id,
b.pdb_name,
a.owner,
a.segment_name,
ROUND(SUM(a.bytes)/1024/1024,2) "DATA MB",
ROUND(SUM(a.inmemory_size)/1024/1024,2) "IN-MEM MB",
ROUND(SUM(a.bytes - a.bytes_not_populated) * 100 / SUM(a.bytes),2) "% IN_MEM",
ROUND(SUM(a.bytes - a.bytes_not_populated) / SUM(a.inmemory_size),2) "COMP RATIO"
FROM v$im_segments a, cdb_pdbs b
WHERE a.con_id = b.pdb_id
GROUP BY a.con_id, b.pdb_name, a.owner, a.segment_name
ORDER BY a.con_id, SUM(a.bytes) desc;6. 其他
6.1. 在RAC环境下查看SCANIP
oracle11gR2 RAC开始引入scan概念,SCAN监听器可以监听到集群中运行的所有数据库,它是实现SCAN负载均衡的原理所在。 一个RAC 支持1~3个SCAN 配置,可以配置域名也可以配置IP地址,如果使用IP地址,有几个IP 配置就集群就会启动几个SCAN listener。 一般通过dns服务器或gns服务器解析scan,也可以使用/etc/hosts文件解析scan,只不过oracle官方不建议这样做。
因为域名可配置为轮询访问IP,三个IP轮流使用。假如我们配置了3个ip供SCAN 使用,同时配置了DNS 解析,监听配置中HOST的值是域名。 当其中一个IP故障不能使用时,dns 会自动解析下一个IP 地址。而且只有一个scan listener.
如果我们通过 /etc/hosts ,配置3个IP地址,并为每个IP配置一个别名,集群启动后就会有三个 scan 监听,当其实一个IP出现问题,无法使用时,对应的监听将失去存在的意义 。那么怎么解决这个问题呢: 使用客户端TAF配置,来实现类似于DNS轮询功能。
切换到 grid 用户下,在SHEll命令中执行。
- 1个scanip情形
# 查看scan的配置信息
~] srvctl config scan
SCAN name: rac-scan1, Network: 1
Subnet IPv4: 192.168.37.0/255.255.255.0/bondeth0, static
Subnet IPv6:
SCAN 1 IPv4 VIP: 192.168.37.7
SCAN VIP is enabled.
# 查看scan的状态以及scan ip所处节点
~] srvctl status scan
SCAN VIP scan1 is enabled
SCAN VIP scan1 is running on node racdb01 <-- 说明scan在节点1上
# 查看scan listener
~] srvctl config scan_listener
SCAN Listeners for network 1:
Registration invited nodes:
Registration invited subnets:
Endpoints: TCP:1521
SCAN Listener LISTENER_SCAN1 exists
SCAN Listener is enabled.- 3个 scanip 情形
# 查看scan的配置信息
~] srvctl config scan
Subnet IPv4: 192.168.21.128/255.255.255.128/bond0, static
Subnet IPv6:
SCAN 1 IPv4 VIP: 192.168.21.135
SCAN VIP is enabled.
SCAN VIP is individually enabled on nodes:
SCAN VIP is individually disabled on nodes:
SCAN 2 IPv4 VIP: 192.168.21.134
SCAN VIP is enabled.
SCAN VIP is individually enabled on nodes:
SCAN VIP is individually disabled on nodes:
SCAN 3 IPv4 VIP: 192.168.21.136
SCAN VIP is enabled.
SCAN VIP is individually enabled on nodes:
SCAN VIP is individually disabled on nodes:
# 查看scan的状态以及scan ip所处节点
~] srvctl status scan
SCAN VIP scan1 is enabled
SCAN VIP scan1 is running on node dbcenter1
SCAN VIP scan2 is enabled
SCAN VIP scan2 is running on node dbcenter2
SCAN VIP scan3 is enabled
SCAN VIP scan3 is running on node dbcenter2
# 查看scan listener
~] srvctl config scan_listener
SCAN Listener LISTENER_SCAN1 exists. Port: TCP:1521,30011
Registration invited nodes:
Registration invited subnets:
SCAN Listener is enabled.
SCAN Listener is individually enabled on nodes:
SCAN Listener is individually disabled on nodes:
SCAN Listener LISTENER_SCAN2 exists. Port: TCP:1521,30011
Registration invited nodes:
Registration invited subnets:
SCAN Listener is enabled.
SCAN Listener is individually enabled on nodes:
SCAN Listener is individually disabled on nodes:
SCAN Listener LISTENER_SCAN3 exists. Port: TCP:1521,30011
Registration invited nodes:
Registration invited subnets:
SCAN Listener is enabled.
SCAN Listener is individually enabled on nodes:
SCAN Listener is individually disabled on nodes:6.3. 查询容器数据库中所有状态为OPEN的用户
SET LINES 300 PAGES 999
COL pdb_name FORMAT A20
COL default_tablespace FORMAT A20
COL temporary_tablespace FORMAT A20
COL username FORMAT A20
SELECT a.con_id,
b.pdb_name,
a.username,
a.account_status,
a.default_tablespace,
a.temporary_tablespace,
to_char(a.last_login,'yyyy-MM-dd hh24:mi:ss') AS last_login
FROM cdb_users a, cdb_pdbs b
WHERE a.con_id = b.pdb_id
AND a.account_status = 'OPEN'
ORDER BY b.pdb_name,a.username;7. RMAN备份相关
7.1. 查询RMAN备份时分配信道对应的操作系统进程号
SET LINES 300 PAGES 999
COLUMN EVENT FORMAT a60
COLUMN SECONDS_IN_WAIT FORMAT 999
COLUMN STATE FORMAT a20
COLUMN CLIENT_INFO FORMAT a30
SELECT p.spid,
sw.event,
sw.seconds_in_wait,
sw.state,
s.client_info
FROM v$session_wait sw, v$session s, v$process p
WHERE s.client_info LIKE '%rman%'
AND s.sid = sw.sid
AND s.paddr = p.addr;7.2. 查询 RMAN 备份进度
SET LINES 300 PAGES 999
COL opname FOR a35
COL start_time FOR a19
SELECT inst_id,
sid,
serial#,opname,
to_char(start_time,'yyyy-mm-dd hh24:mi:ss') AS start_time,
sofar,
totalwork,
round(sofar/totalwork*100,2) AS "%complete",
ceil(elapsed_seconds/60) AS elapsed_mi
FROM gv$session_longops
WHERE opname LIKE 'RMAN%'
AND totalwork <> 0
ORDER BY start_time ASC;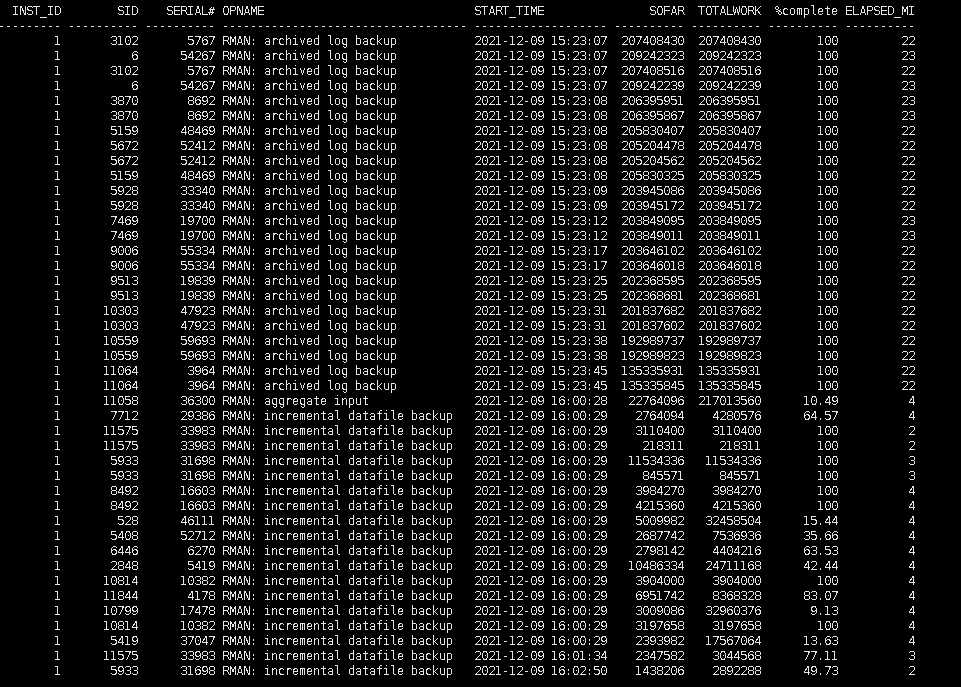
7.3. 查看每天RMAN备份大小
SET LINES 300 PAGES 999
SELECT TO_CHAR(start_time, 'yyyy-mm-dd') AS start_time,
TO_CHAR(start_time, 'day') AS week_day,
ROUND(SUM(output_bytes) / 1024 / 1024 / 1024, 2) AS size_gb
FROM v$backup_set_details
GROUP BY TO_CHAR(start_time, 'yyyy-mm-dd'),TO_CHAR(start_time, 'day')
ORDER BY start_time DESC;7.4. 查看数据库是否开启了块改变跟踪
SET LINES 300 PAGES 999
COL FILENAME FOR A60
SELECT * FROM v$block_change_tracking;- RAC环境中开启块改变跟踪
ALTER DATABASE ENABLE BLOCK CHANGE TRACKING USING FILE '+ARCHDG/etdb/block_change_tracking.log';- 单实例环境
alter database enable block change tracking using file '/dbData/OracleBack/rman_change_track.f' reuse;- 关闭块改变跟踪
ALTER DATABASE DISABLE BLOCK CHANGE TRACKING;- 查看 block change tracking 文件的位置及大小
SET LINES 300 PAGES 999
COLUMN filename FORMAT a60;
SELECT * FROM v$block_change_tracking;
8. 元数据相关
8.1. 查询某个用户下表的属性
8.2. 查询某个用户下字段的属性
8.3. 获取某个用户下主键、唯一性约束和检查约束的创建语句
SELECT dbms_metadata.GET_DEPENDENT_DDL('CONSTRAINT',table_name,owner)
FROM dba_constraints a
WHERE a.owner = UPPER('&请输入用户名')
AND a.constraint_type NOT IN ('R','?','O')
GROUP BY a.owner,a.table_name;8.4. 查看表与索引的创建语句
SET heading off
SET echo off
SET pages 999
SET long 90000
spool get_TABLE_ddl.sql
SELECT dbms_metadata.get_ddl('TABLE','TABLE_NAME'[,'SCHEMA_NAME']) FROM dual;
SELECT dbms_metadata.get_ddl('INDEX','INDEX_NAME'[,'SCHEMA_NAME']) FROM dual;
spool off;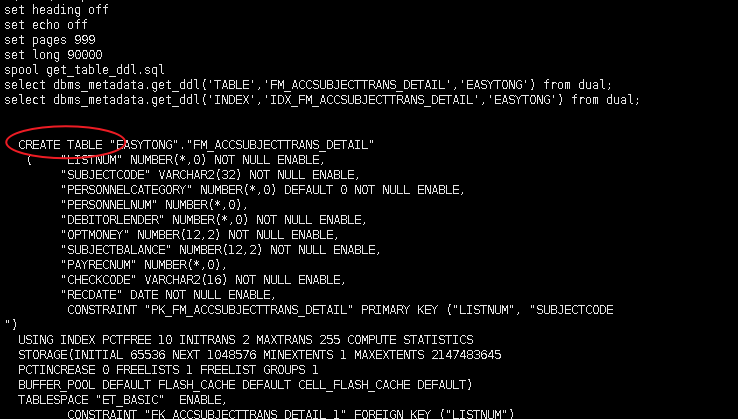
8.5. 查看索引占用的存储大小
SET LINES 300 PAGES 999
COL tablespace_name FORMAT a12
COL owner FORMAT a12
COL segment_name FORMAT a30
COL partition_count FORMAT 99999999
COL segment_size FORMAT 999999999999.99
SELECT tablespace_name AS tablespace_name,
owner AS owner,
segment_name AS segment_name,
NVL(COUNT(partition_name),0) AS partition_count,
sum(bytes)/1024/1024 AS segment_size
FROM dba_segments
WHERE tablespace_name = UPPER('&TablespaceName')
GROUP BY Tablespace_name,owner,segment_name
ORDER BY 2,3;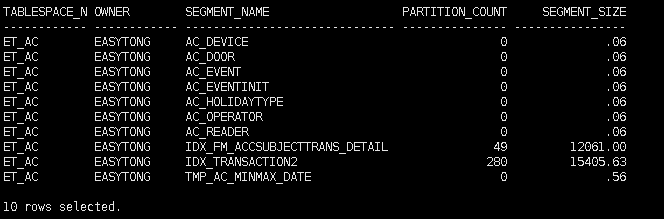
8.6. 获取某个用户下外键约束的创建语句
SELECT dbms_metadata.GET_DEPENDENT_DDL('REF_CONSTRAINT',table_name,owner)
FROM dba_constraints a
WHERE a.owner = UPPER('&请输入用户名')
AND a.constraint_type = 'R'
GROUP BY a.owner, a.table_name;8.7. 启用/禁用某个用户下外键约束的语句
-- 启用外键约束
SELECT 'ALTER TABLE ' || table_name || ' ENABLE CONSTRAINT '|| constraint_name || ';'
FROM dba_constraints
WHERE owner = UPPER('&请输入用户名')
AND constraint_type = 'R';
-- 禁用外键约束
SELECT 'ALTER TABLE ' || table_name || ' DISABLE CONSTRAINT ' || constraint_name ||';'
FROM dba_constraints
WHERE owner = UPPER('&请输入用户名')
AND constraint_type = 'R';8.8. 通过链接数据库获取插入表的SQL
WITH t
AS (SELECT x.table_name AS table_name,
listagg(x.column_name,',') WITHIN GROUP(ORDER BY x.table_name,x.column_id) AS table_column_set
FROM user_tab_columns x
GROUP BY x.table_name)
SELECT 'insert into ' || t.table_name || '(' || t.table_column_set || ')' ||
' select ' || t.table_column_set ||
' from ' || t.table_name || '@to_qdu;'
FROM t;023. 查询数据库的密码生命同期
SET LINES 300 PAGES 999
COL profile FOR a30
COL resource_name FOR a40
COL limit FOR a40
SELECT *
FROM dba_profiles
WHERE resource_name LIKE '%PASSWORD%';025. 查询角色及系统权限
-- 查询系统中的角色
SELECT *
FROM dba_roles a
WHERE a.role = UPPER('execute_catalog_role');
-- 查询某个用户或角色拥有的角色(或拥有某个角色的用户或角色)
SELECT *
FROM dba_role_privs a
WHERE a.granted_role = UPPER('connect')
OR a.grantee = 'DBA';
-- 查询当前登陆用户拥有的角色权限
SELECT *
FROM user_role_privs a;
-- 查询某个用户或角色拥有的系统权限
SET LINES 300 PAGES 999
COL GRANTEE FOR A30
SELECT *
FROM dba_sys_privs a
WHERE a.grantee = UPPER('connect');
-- 查询当前登陆用户拥有的系统权限
SELECT *
FROM user_sys_privs a;角色不一定包含系统权限,比如 EXECUTE_CATALOG_ROLE 角色。
预定义数据库角色(常见的5个):
| 角色名称 | 角色用途 |
|---|---|
| CONNECT | 基本的用户角色,允许授权者链接到数据库,然后在相关的模式中创建表、视图、同义词、序列和一些其他的对象类型。 |
| RESOURCE | 建议用于典型的应用开发人员。该角色允许授权者在相关的模式中创建表、序列、数据簇、过程、函数、包、触发器、对象类型、基于函数的索引和用户自定义的操作符。 |
| DBA | 建议用户管理员。该角色允许授权者执行任何数据库功能,因为它包含了说有的系统权限。此外,改DBA角色的授权者,可以向任何其他数据库用户或角色授予任何系统权限。 |
| SELECT_CATALOG_ROLE | 该角色允许授权者查询管理员(DBA)数据字典视图。 |
| EXECUTE_CATALOG_ROLE | 该角色允许授权者运行预制的DBMS工具包。 |