
1. Join连接模式与执行顺序
1.1. 语法
SELECT <row_list>
FROM <left_table>
<inner|left|right> JOIN <right_table>
ON <join condition>
WHERE <where_condition>
1.2. 连接模式与结果集
Join主要分为外连接、内连接和自然连接
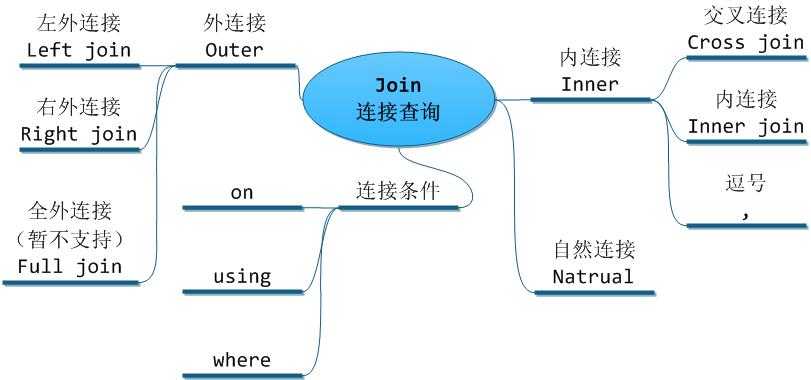
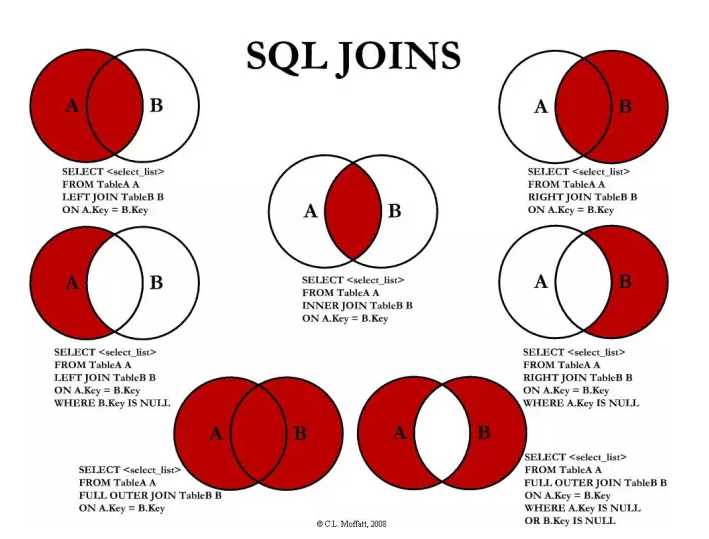
- left join :左连接,返回左表中所有的记录以及右表中连接字段相等的记录。
- right join :右连接,返回右表中所有的记录以及左表中连接字段相等的记录。
- inner join: 内连接,又叫等值连接,只返回两个表中连接字段相等的行。
- full join:外连接,返回两个表中的行:left join + right join。
- cross join:结果是笛卡尔积,就是第一个表的行数乘以第二个表的行数。
1.3. 执行顺序
第一步:执行FROM子句对两张表进行笛卡尔积操作
第二步:执行ON子句过滤掉不满足条件的行
第三步:JOIN 添加外部行
第四步:WHERE条件过滤
第五步:SELECT
SQL语句里第一个被执行的总是FROM子句:
- FROM:对左右两张表执行笛卡尔积,产生第一张表vt1。行数为 n * m(n为左表的行数,m为右表的行数

- ON:根据ON的条件逐行筛选vt1,将结果插入vt2中
-
JOIN:添加外部行,如果指定了LEFT JOIN(LEFT OUTER JOIN),则先遍历一遍左表的每一行,其中不在vt2的行会被插入到vt2,该行的剩余字段将被填充为NULL,形成vt3;如果指定了RIGHT JOIN也是同理。但如果指定的是INNER JOIN,则不会添加外部行,上述插入过程被忽略,vt2=vt3(所以INNER JOIN的过滤条件放在ON或WHERE里 执行结果是没有区别的。)
-
WHERE:对vt3进行条件过滤,满足条件的行被输出到vt4
-
SELECT:取出vt4的指定字段到vt5
2. 联表算法
MySQL 的联表算法是基于嵌套循环算法(nested-loop algorithm)而衍生出来的一系列算法,根据不同条件而选用不同的算法,具体和MySQL索引有一定关系。
在使用索引关联的情况下,有 Index Nested-Loop join 和 Batched Key Access join 两种算法;在未使用索引关联的情况下,有 Simple Nested-Loop join 和 Block Nested-Loop join 两种算法。
2.1. Simple Nested-Loop(SNLJ,普通嵌套循环连接)
简单嵌套循环,简称 SNL;逐条逐条匹配,伪代码如下:
For each row r in R do -- 扫描R表(驱动表)
For each row s in S do -- 扫描S表(被驱动表)
If r and s satisfy the join condition -- 如果r和s满足join条件
Then output the tuple <r, s> -- 返回结果集

R表为外部表(驱动表),S表为内部表(被驱动表),可以看到从 R 中分别取出每一条记录去匹配 S 表的列,然后合并数据,对 S 表进行 R 表的行数次的访问,对数据库开销非常大,性能极差。(这种算法简单粗暴,但毫无性能可言,时间性能上来说是 n(R表中记录数) 的 m(S表的数量) 次方,所以 MySQL 做了优化,联表查询的时候不会出现这种算法,即使在无 WHERE 条件且 ON 的连接键上无索引时,也不会选用这种算法。)
假设在两张表R和S上进行联接的列都不含有索引,外表的记录数为RN,内表的记录数位SN。SNLJ的开销如下表所示:
| 开销统计 | SNLJ |
|---|---|
| 外表扫描次数(O) | 1 |
| 内表扫描次数(I) | RN |
| 读取记录数(R) | RN + SN * RN |
| Join比较次数(M) | SN * RN |
| 回表读取记录次数(F) | 0 |
举个例子,当 R 有 30 行符合条件的数据,而 S 有 50 行数据,则需要对 S 执行全表扫描 30 次,总共需要读取 S 表 50 * 30 = 1500 数据行。
2.2. Block Nested-Loop(BNLJ,缓存块嵌套循环连接)
缓存块嵌套循环连接,简称 BNL,是对 INL 的一种优化;一次性缓存多条驱动表的数据,然后拿 Join Buffer 里的数据批量与内层循环读取的数据进行匹配。所以缓存块嵌套循环连接算法意在通过一次性缓存驱动表的多条数据,以此来减少被驱动表的扫表次数,从而达到提升性能的目的。 当被驱动表在连接键上无索引且被驱动表在 WHERE 过滤条件上也没索引时,常常会采用此种算法来完成联表。 伪代码如下:
For each tuple r in R do -- 扫描外表R
store used columns as p from R in Join Buffer -- 将部分或者全部R的记录保存到Join Buffer中,记为p
For each tuple s in S do -- 扫描内表S
If p and s satisfy the join condition -- p与s满足join条件
Then output the tuple <r, s> -- 返回为结果集

Block Nested-Loop Join对比Simple Nested-Loop Join多了一个中间处理的过程,也就是join buffer, 使用join buffer 将驱动表的查询JOIN相关列都给缓冲到了JOIN BUFFER当中,然后批量与被驱动表进行比较。这一来实现的话,可以将多次比较合并到一次,降低了非驱动表的访问频率(遍历一次被驱动表就可以批量匹配一次Join Buffer里面的驱动表数据)。
假设在两张表R和S上进行联接的列都不含有索引,外表的记录数为RN,内表的记录数位SN。BNLJ的开销如下表所示:
| 开销统计 | SNLJ | BNLJ |
|---|---|---|
| 外表扫描次数(O) | 1 | 1 |
| 内表扫描次数(I) | RN | RN * used_column_size / join_buffer_size + 1 |
| 读取记录数(R) | RN + SN * RN | RN + SN * I |
| Join比较次数(M) | SN * RN | SN * RN |
| 回表读取记录次数(F) | 0 | 0 |
备注:其中 used_column_size 为 join 字段总大小,join_buffer_size 为 buffer 的大小。
举个例子,当 Table1 有 30 行符合条件的数据,而 Table2 有 50 行数据,没有 Join Buffer时内层循环的读表次数应该是 30 次,如果 Join Buffer 可用并可以存 10 条记录(Join Buffer 存储的是驱动表中参与查询的列,包括 SELECT 的列、ON 的列、WHERE 的列,而不是驱动表中整行整行的完整记录:Only columns of interest to the join are stored in the join buffer, not whole rows.),那么需要对 Table2 执行全表扫描 30 / 10 = 3 次,总共需要读取 Table2 表 50 * 3 = 150 数据行。
Block Nested-Loop Join极大的避免了被驱动表的扫描次数,如果Join Buffer可以缓存驱动表的所有数据,那么被驱动表的扫描仅需一次,这和Hash Join非常类似。但是Block Nested-Loop Join依然没有解决的是Join比较的次数,其仍然通过Join判断式进行比较。另外,如果这个被驱动表是一个大的冷数据表,除了会导致 IO 压力大以外,还会对 buffer pool产生严重的影响!
2.3. Index Nested-Loop(INLJ,索引嵌套循环连接)
索引嵌套循环,简称 INL,是基于被驱动表的索引进行连接的算法;驱动表的记录逐条与被驱动表的索引进行匹配,避免和被驱动表的每条记录进行比较,减少了对被驱动表的匹配次数。伪代码如下:
For each row r in R do -- 扫描R表
lookup s in S index -- 查询S表的索引(固定3~4次IO,B+树高度)
If find s == r -- 如果r匹配了索引s
Then output the tuple <r, s> -- 返回结果集
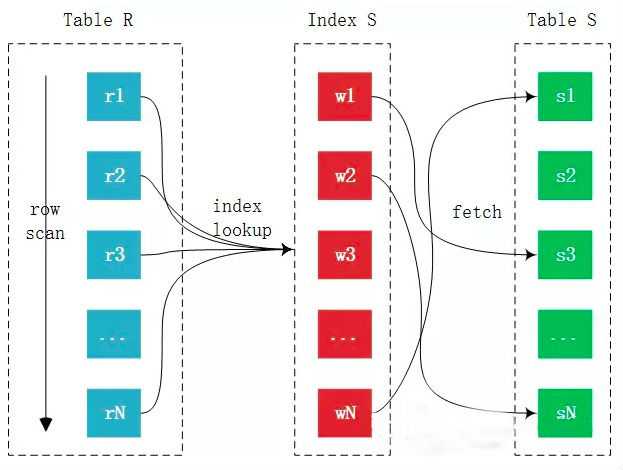
可以看到外表中的每条记录通过内表的索引进行访问,就是读取外部表一行数据,然后去内部表索引进行二分查找匹配;而一般B+树的高度为 3~4 层,也就是说匹配一次的io消耗也就 3~4 次,因此索引查询的成本是比较固定的,故优化器都倾向于使用记录数少的表作为驱动表。故INLJ的算法成本如下表所示:
| 开销统计 | SNLJ | BNLJ | INLJ |
|---|---|---|---|
| 外表扫描次数(O) | 1 | 1 | 1 |
| 内表扫描次数(I) | RN | RN * used_column_size / join_buffer_size + 1 | 0 |
| 读取记录数(R) | RN + SN * RN | RN + SN * I | RN + Smatch |
| Join比较次数(M) | SN * RN | SN * RN | RN * IndexHeight |
| 回表读取记录次数(F) | 0 | 0 | Smatch (if possible) |
上表Smatch表示通过索引找到匹配的记录数量。同时可以发现,通过索引可以大幅降低内表的Join的比较次数,每次比较1条外表的记录,其实就是一次indexlookup(索引查找),而每次index lookup的成本就是树的高度,即IndexHeight。
2.4. Batched Key Access(BKA,批量键访问联接)
Index Nested-Loop Join虽好,但是通过辅助索引进行联接后需要回表,这里需要大量的随机I/O操作。若能优化随机I/O,那么就能极大的提升Join的性能。为此,MySQL 5.6(MariaDB 5.3)开始支持Batched Key Access Join算法(简称BKA),该算法通过常见的空间换时间,随机I/O转顺序I/O,以此来极大的提升Join的性能。
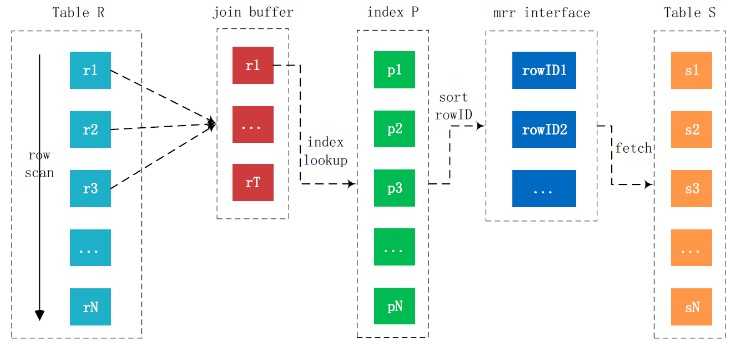
Batched Key Access Join算法的工作步骤如下:
- 将外部表中相关的列放入Join Buffer中。
- 批量的将Key(索引键值)发送到Multi-Range Read(MRR)接口。
- Multi-Range Read(MRR)通过收到的Key,根据其对应的ROWID进行排序,然后再进行数据的读取操作。
- 返回结果集给客户端。
Batched Key Access Join算法的本质上来说还是Simple Nested-Loops Join算法,其发生的条件为内部表上有索引,并且该索引为非主键,并且联接需要访问内部表主键上的索引。这时Batched Key Access Join算法会调用Multi-Range Read(MRR)接口,批量的进行索引键的匹配和主键索引上获取数据的操作,以此来提高联接的执行效率,因为读取数据是以顺序磁盘IO而不是随机磁盘IO进行的。
3. 总结
总的来说,应用 join 需要注意:
- 用来进行 join 的字段要加索引,会触发 INLJ 算法,如果是主键的聚簇索引,性能最优。
- 如果无法使用索引,那么注意调整 join buffer 大小,适当调大些。
- 小结果集驱动大结果集。用数据量小的表去驱动数据量大的表,这样可以减少内循环个数,也就是被驱动表的扫描次数。
- 联表顺序,不是两两联合之后,再去联合第三张表,而是驱动表的一条记录穿到底,匹配完所有关联表之后,再取驱动表的下一条记录重复联表操作。
参考:
本站案例:MariaDB执行计划案例
MySQL联接查询算法:https://blog.csdn.net/wakeupwakeup/article/details/98757148
SQL 之 联表细节: https://jhrs.com/2019/33621.html
MySQL JOIN 的执行过程: https://www.cnblogs.com/youzhibing/p/12012952.html